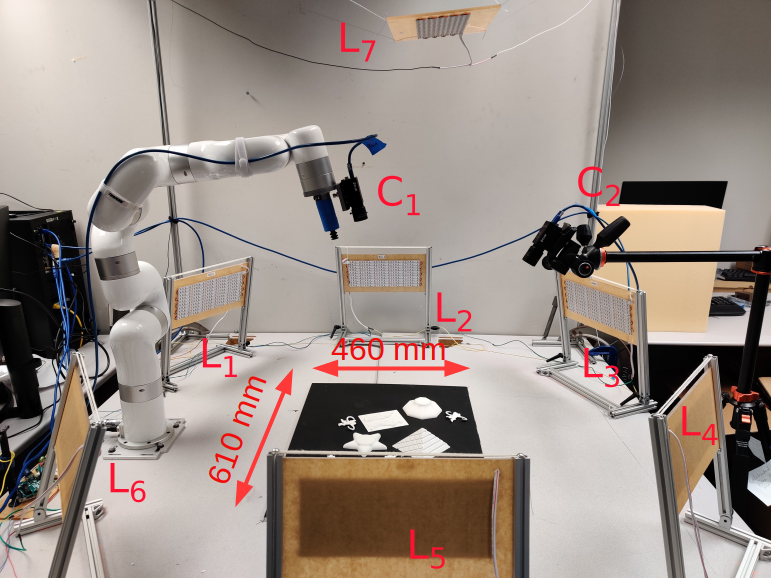




Controlling illumination can generate high quality information about object surface normals and depth discontinuities at a low computational cost. In this work we demonstrate a robot workspace-scaled controlled illumination setup that generates high quality information for table top scale objects for robotic manipulation. With our low angle of incidence directional illumination setup we can precisely capture surface normals and depth discontinuities of Lambertian objects. We demonstrate three use cases of our setup for robotic manipulation. We show that 1) by using the captured information we can perform general purpose grasping with a single point vacuum gripper, 2) we can visually measure the deformation of known objects, and 3) we can estimate pose of known objects and track unknown objects in the robot's workspace.
Firefox users: Please use the pop-out button if inline videos are not working.



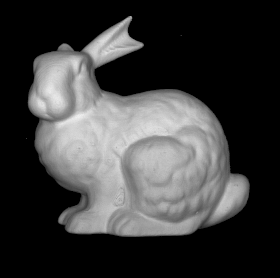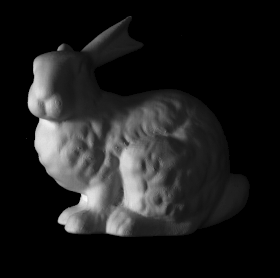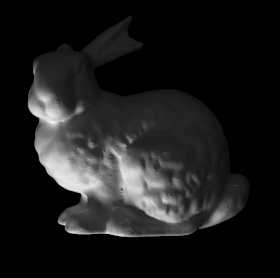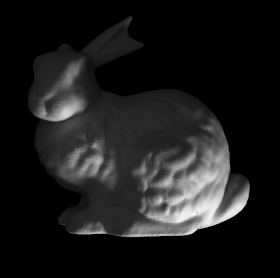



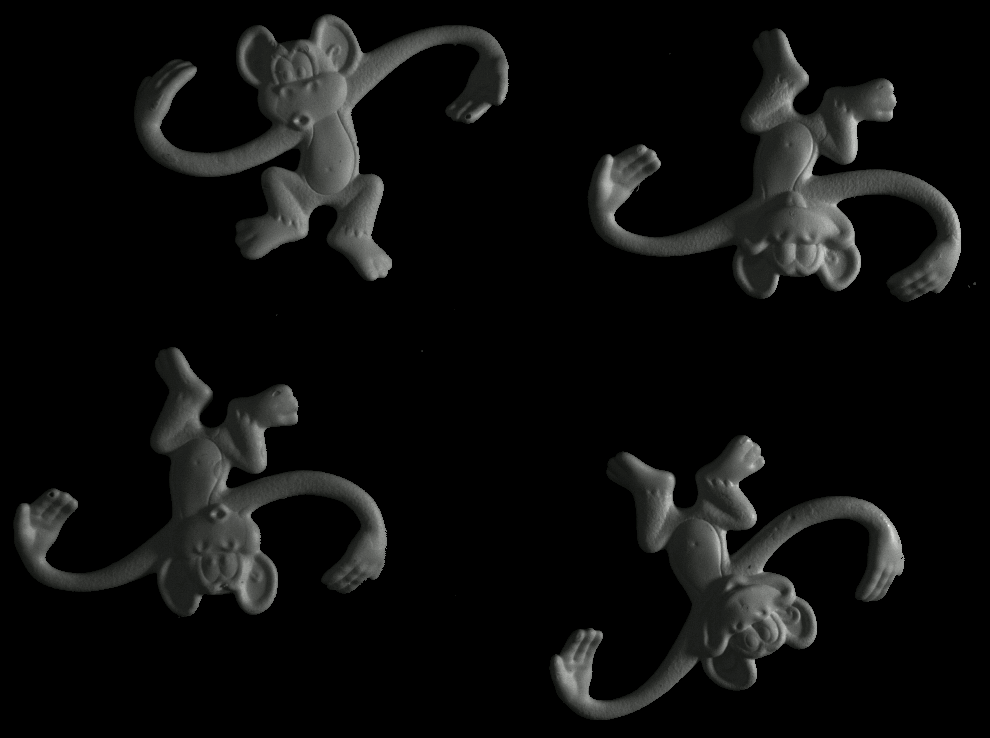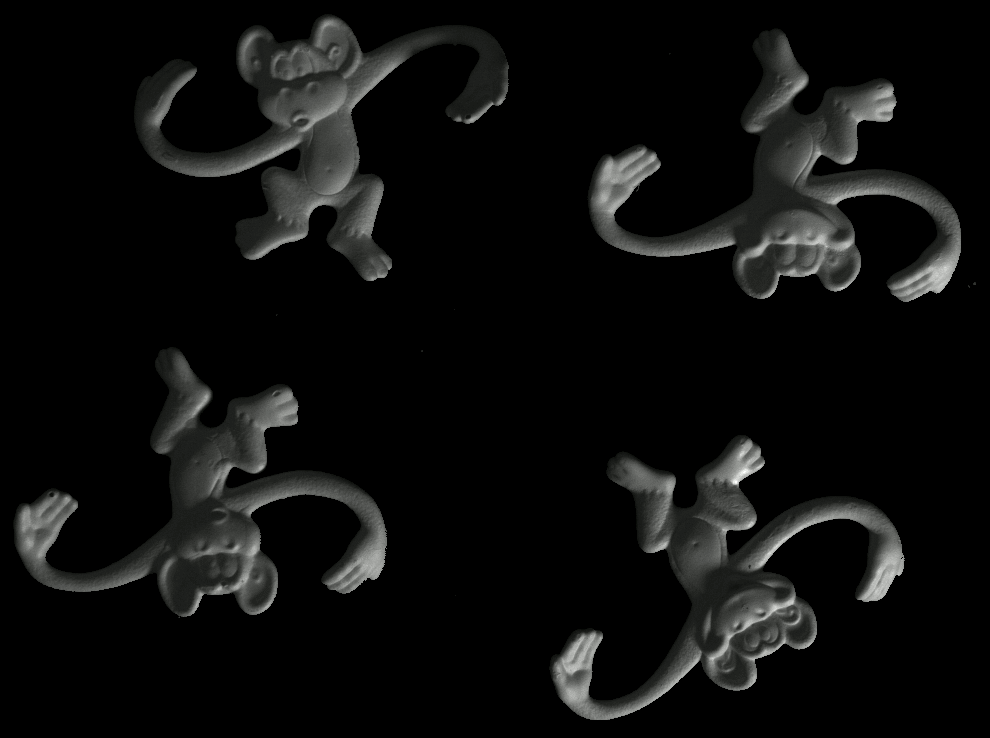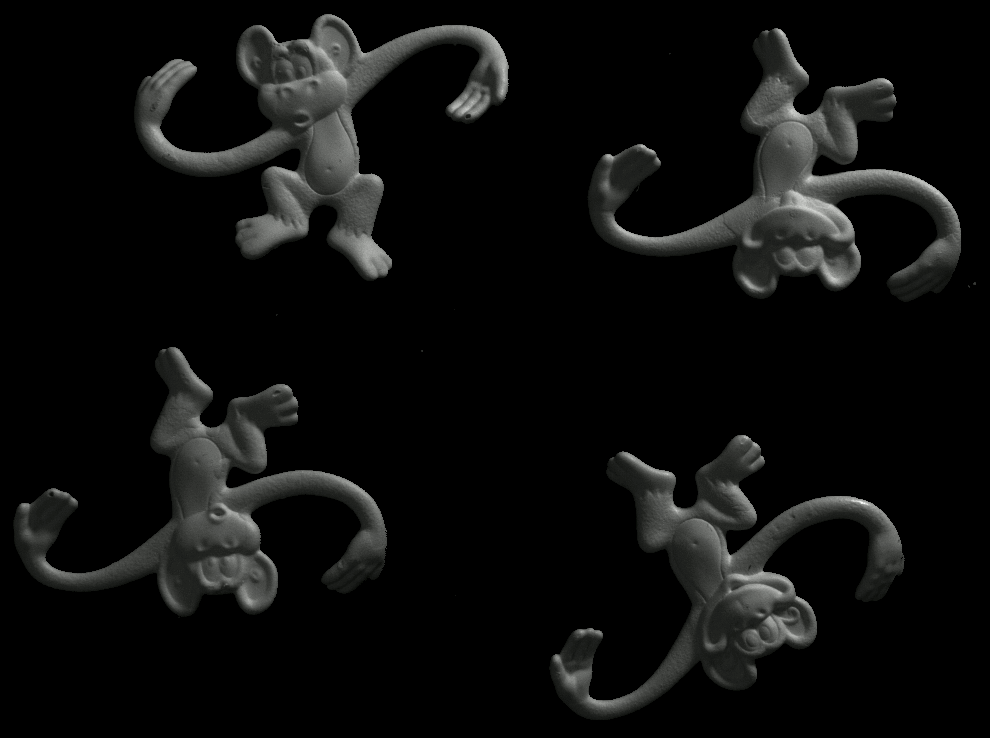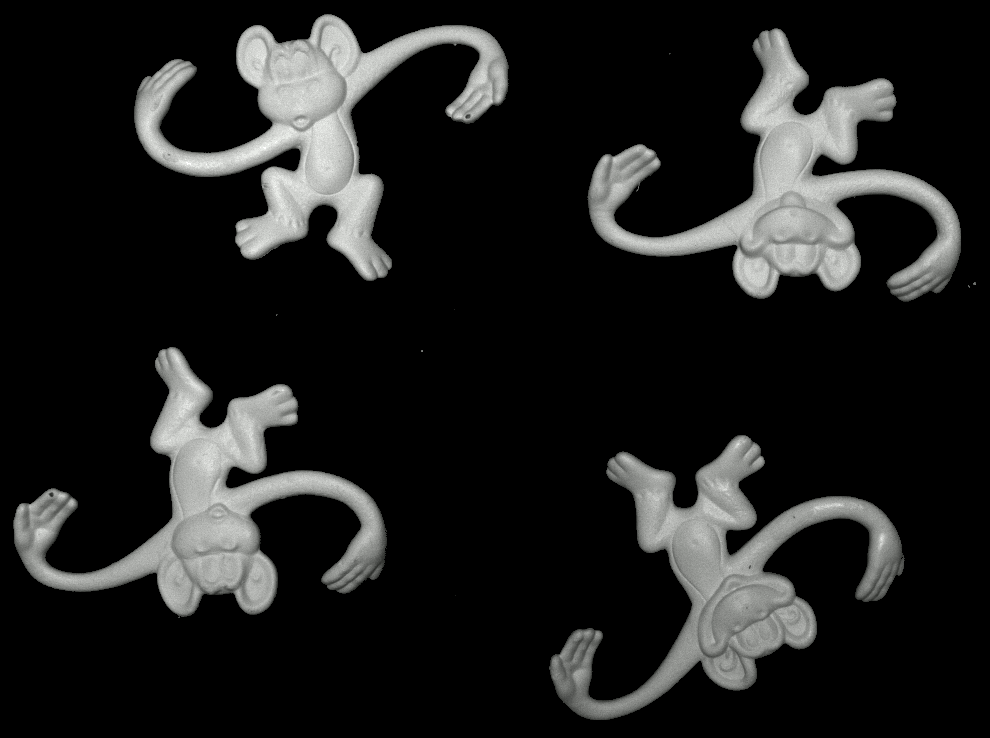







Some more single view 3D reconstructions from our pipeline.
Comparison between ground truth .
Firefox users: Please use the pop-out button if inline videos are not working.
The robot demonstrations have not been sped up.
Firefox users: Please hit refresh if the comparators are frozen.












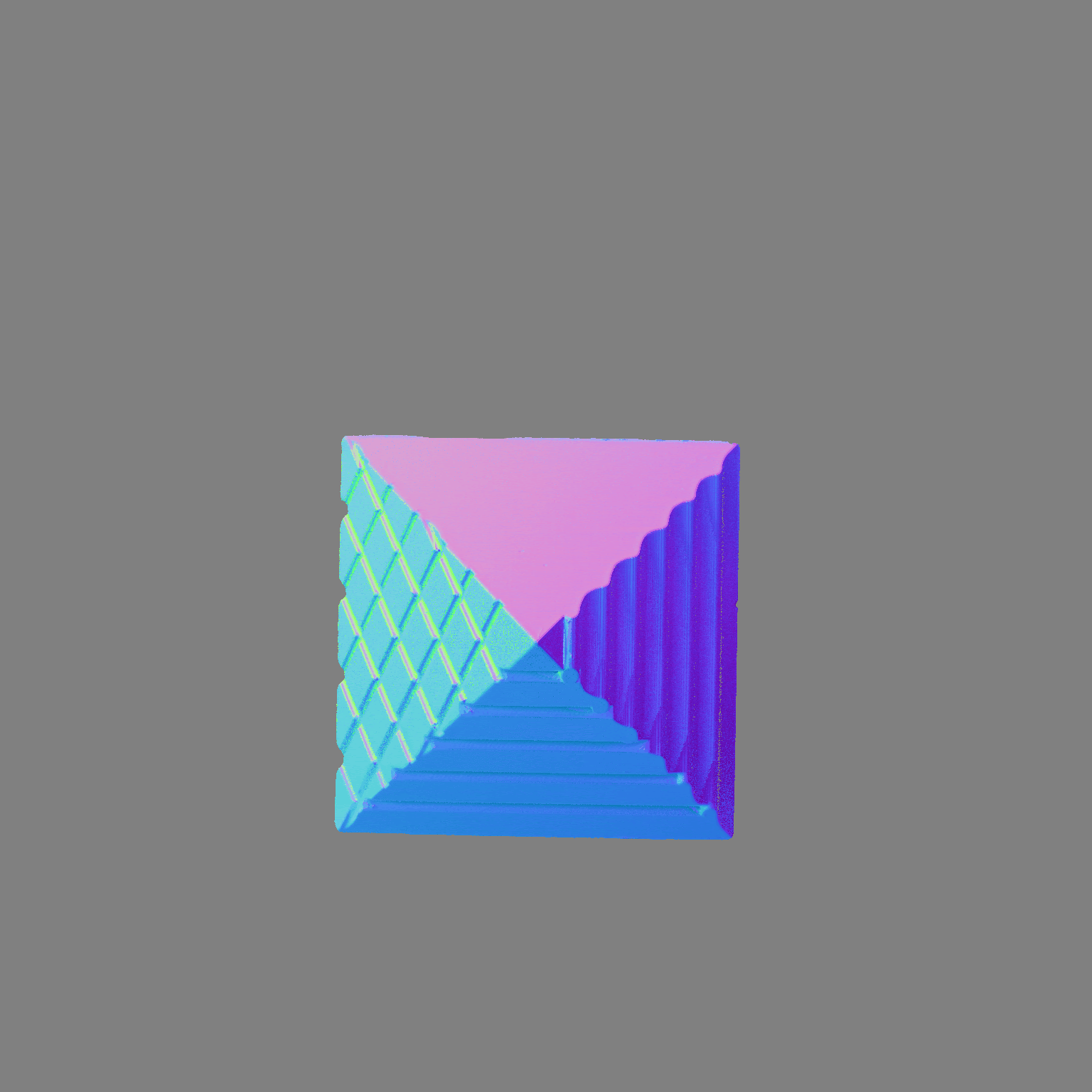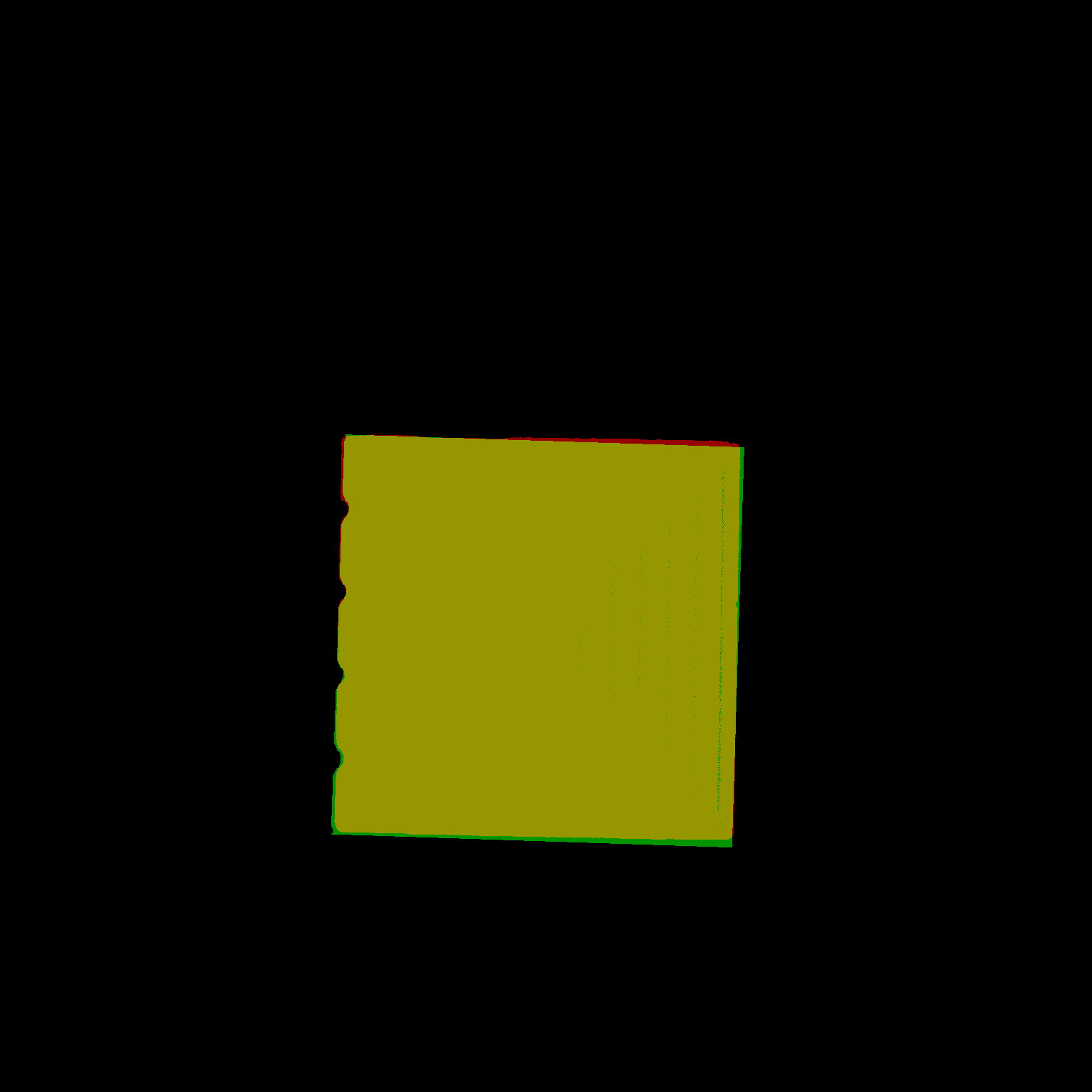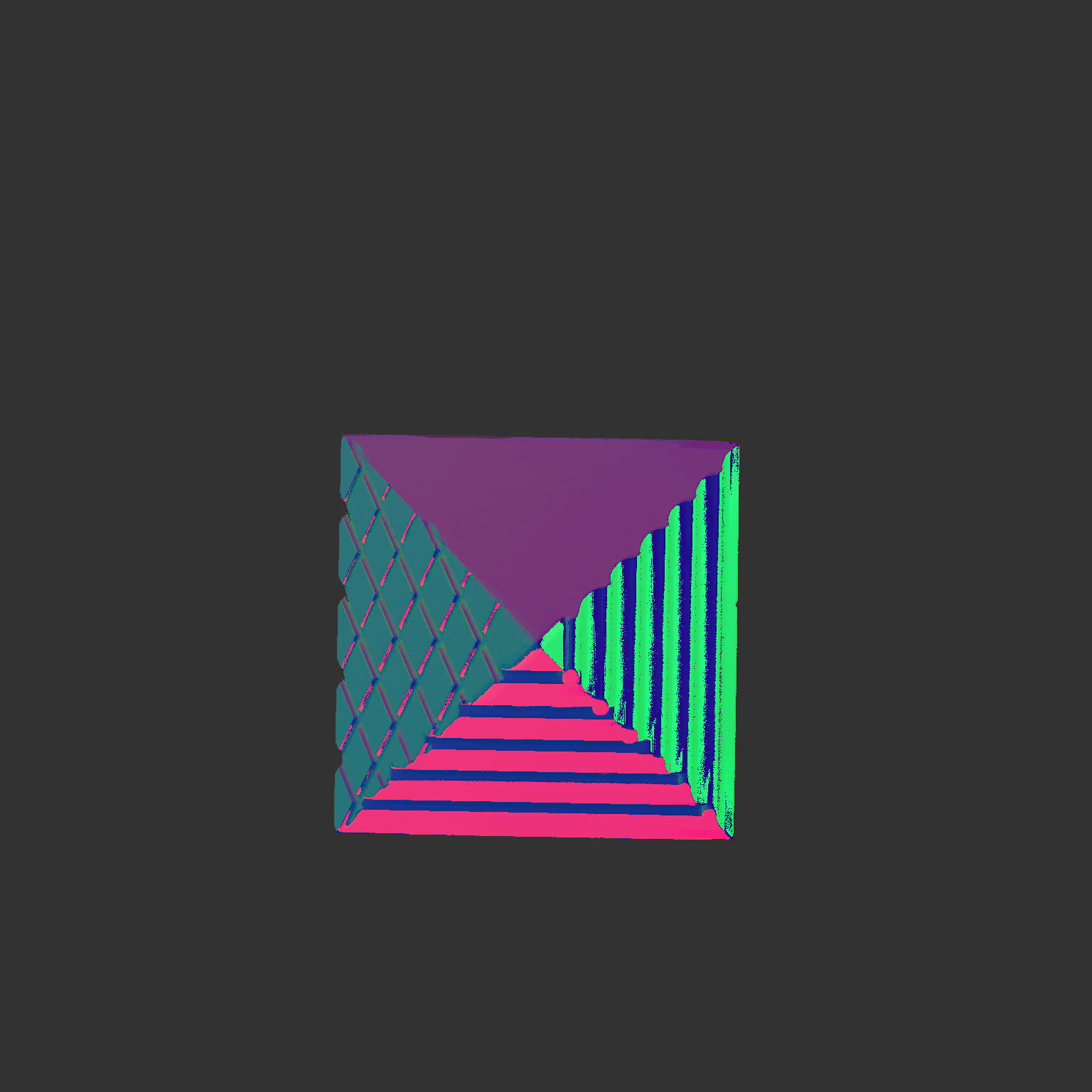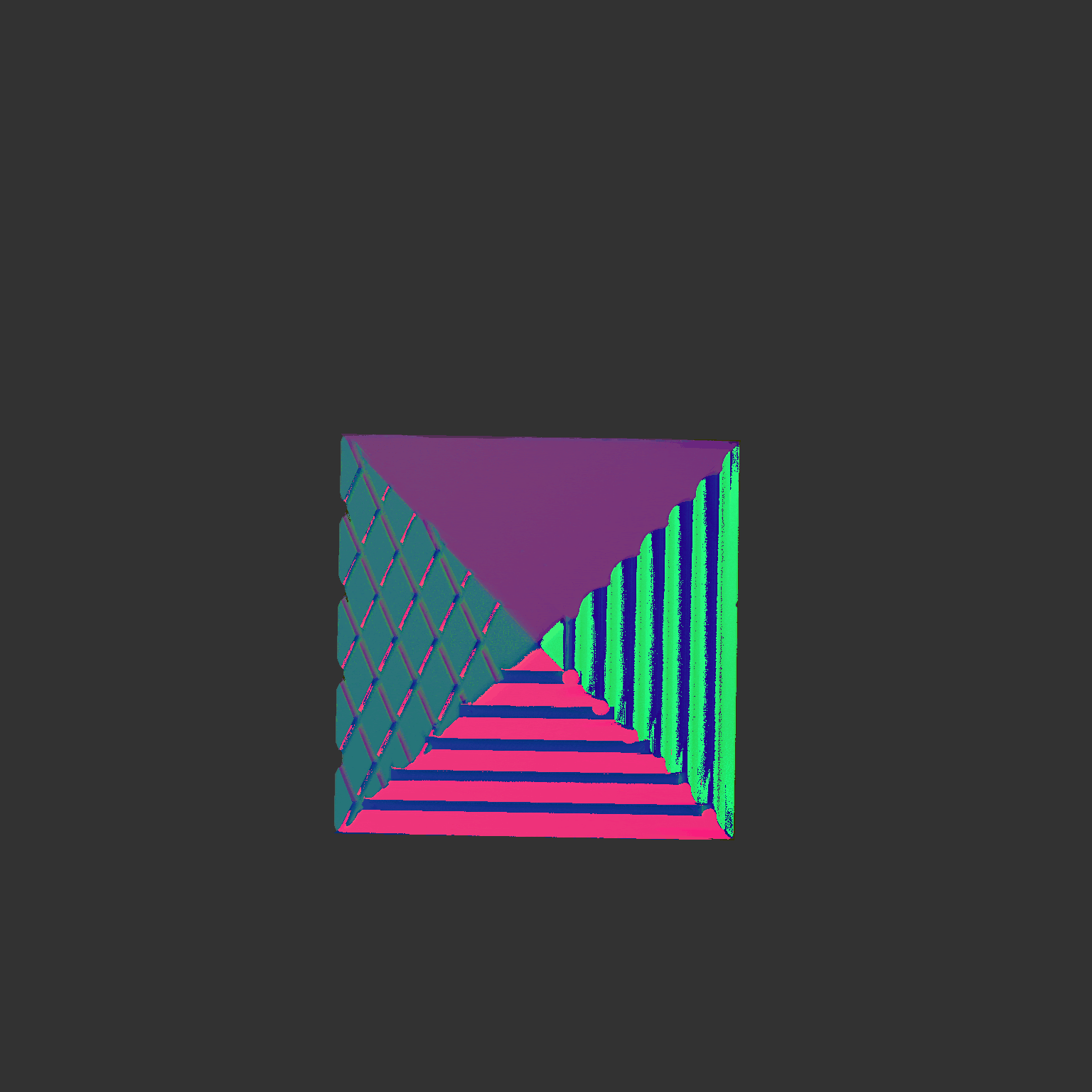
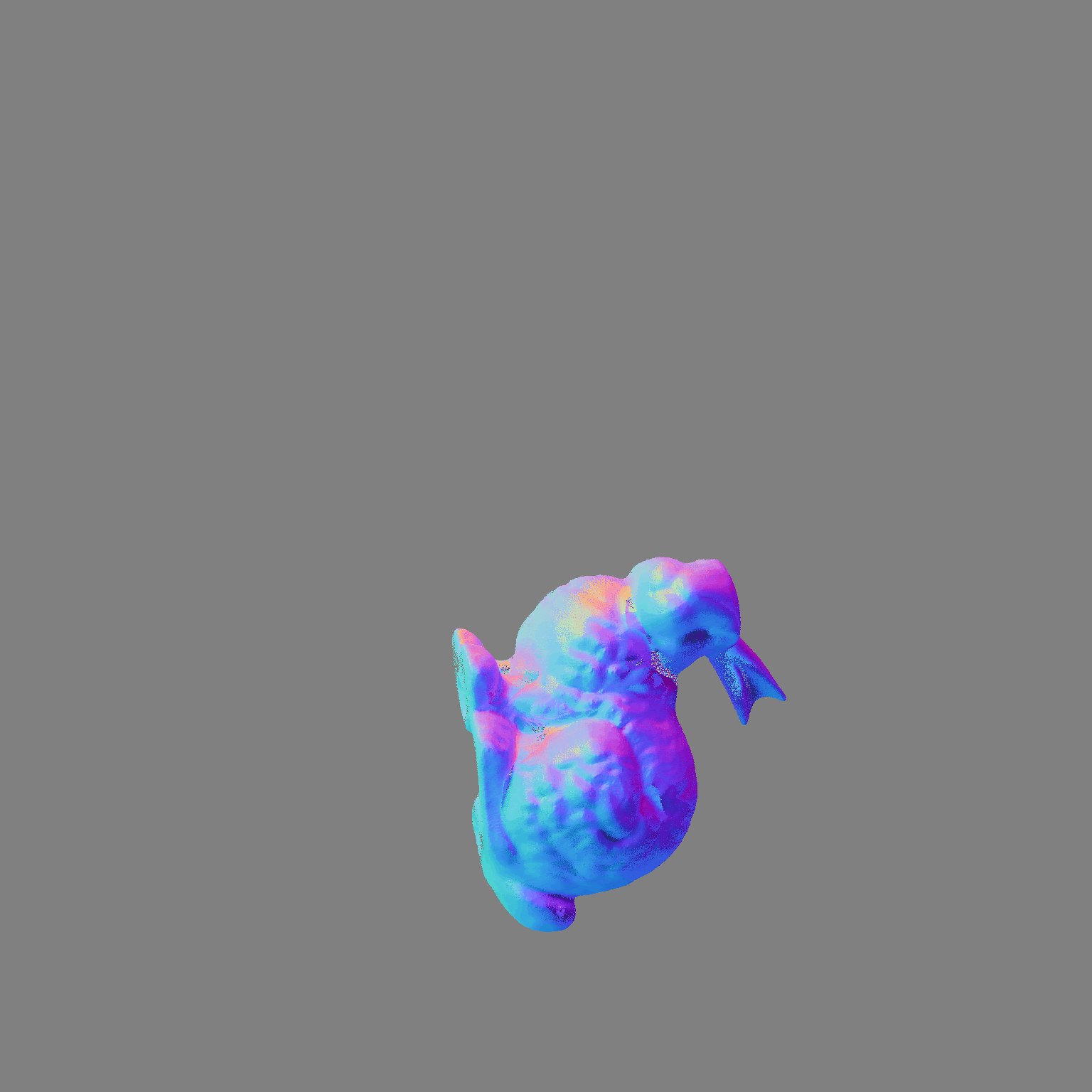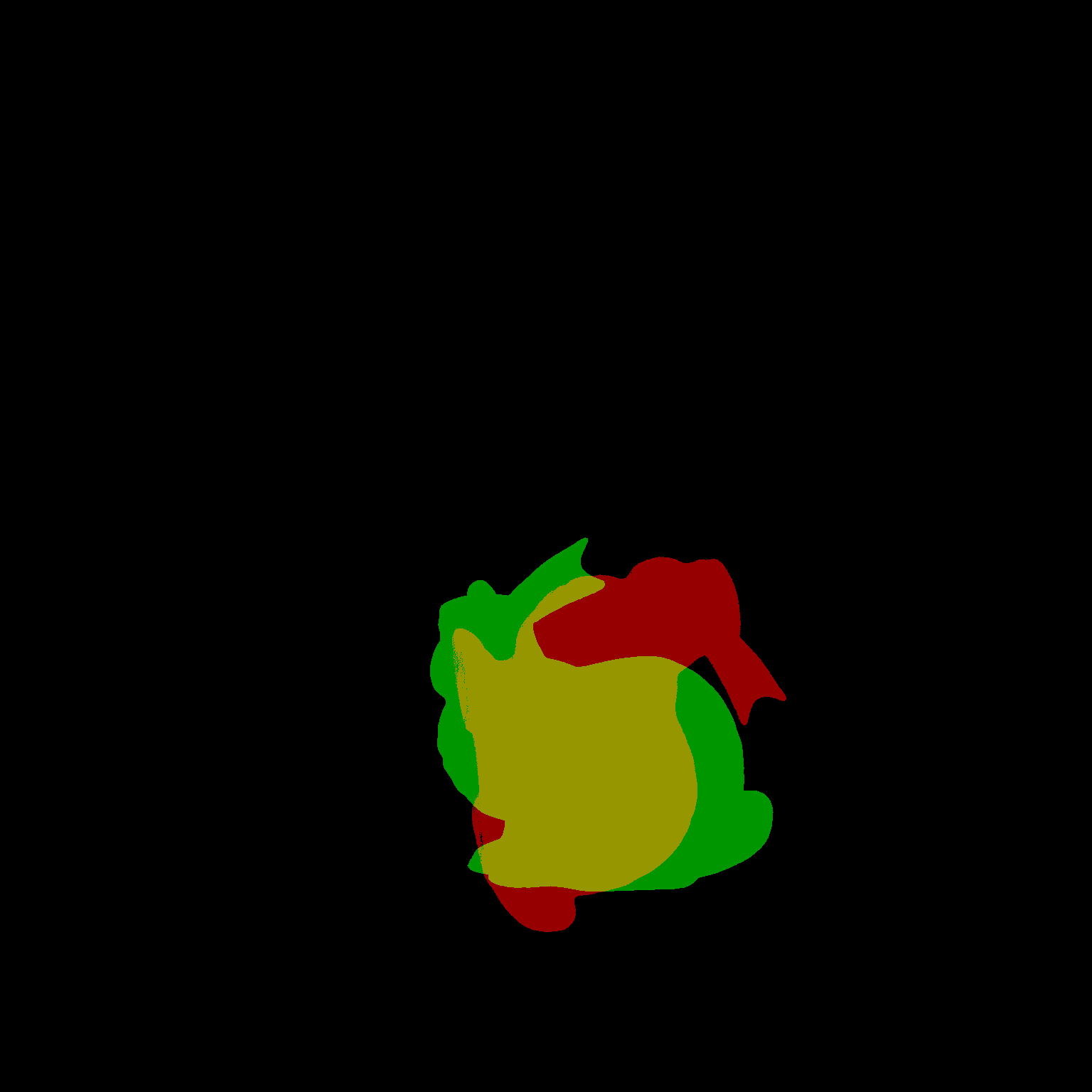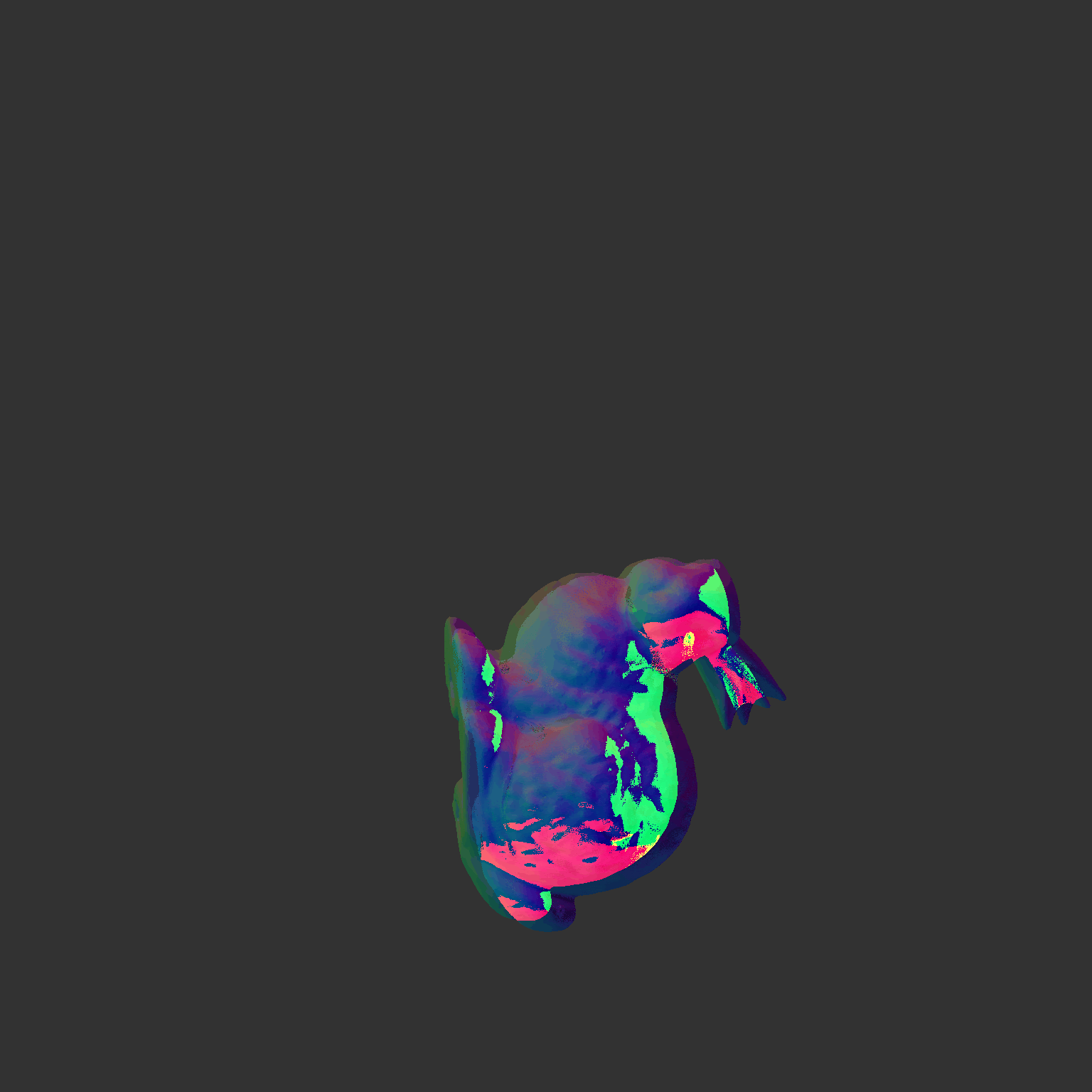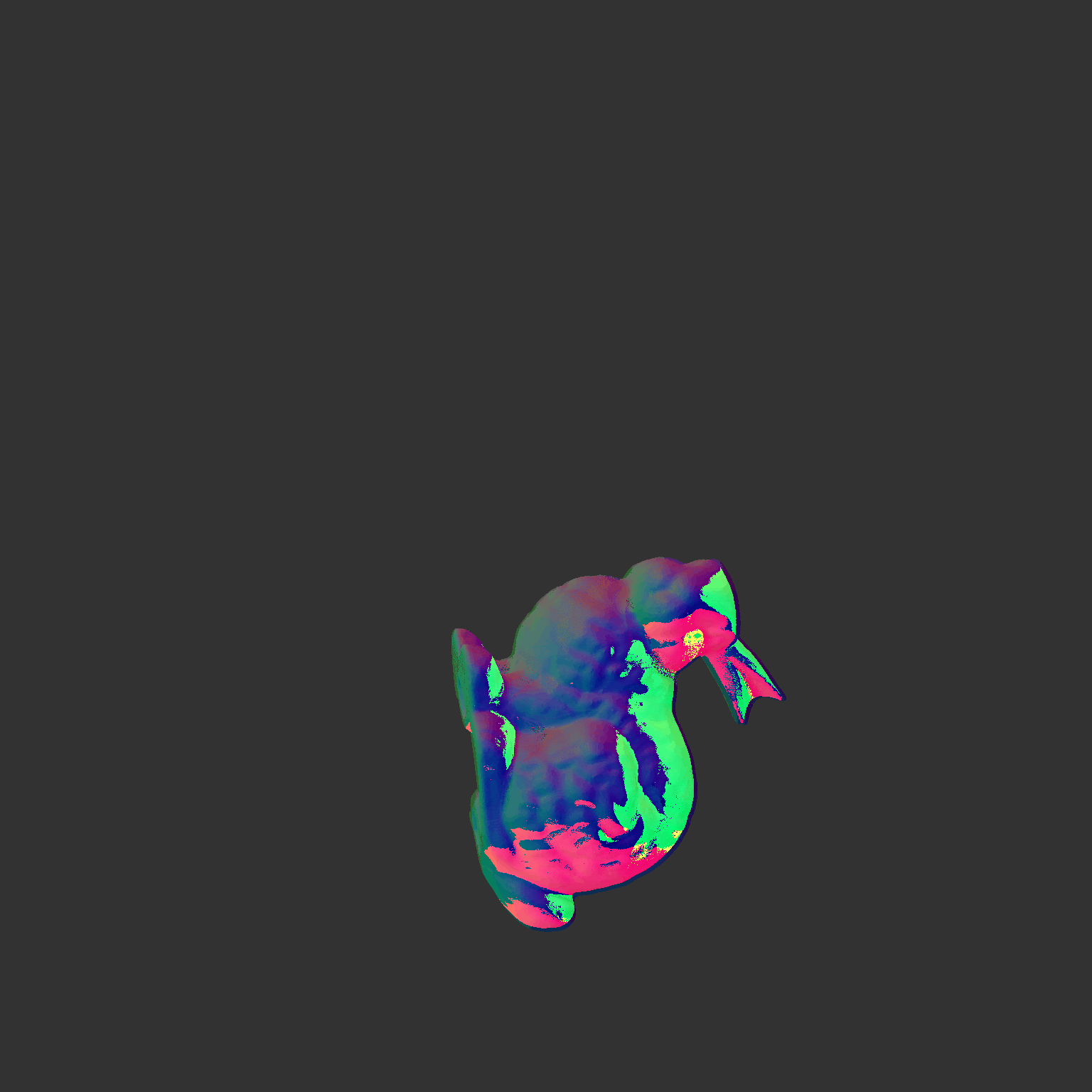





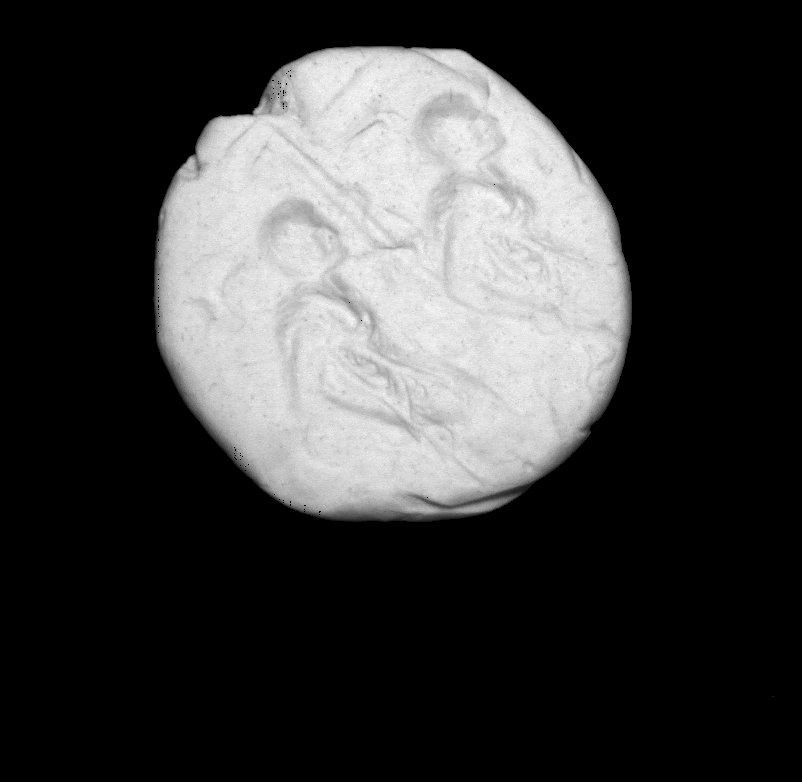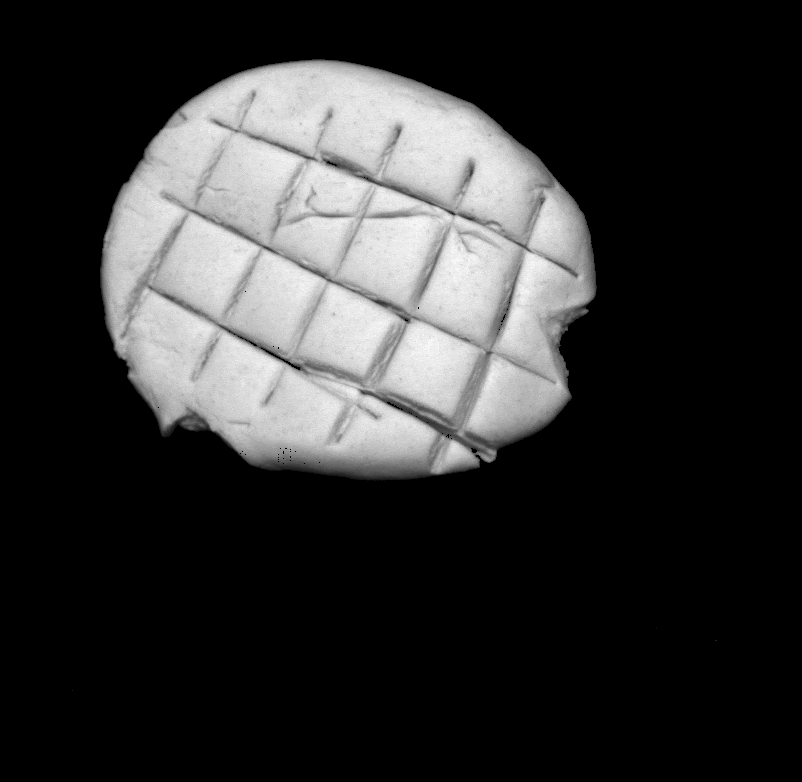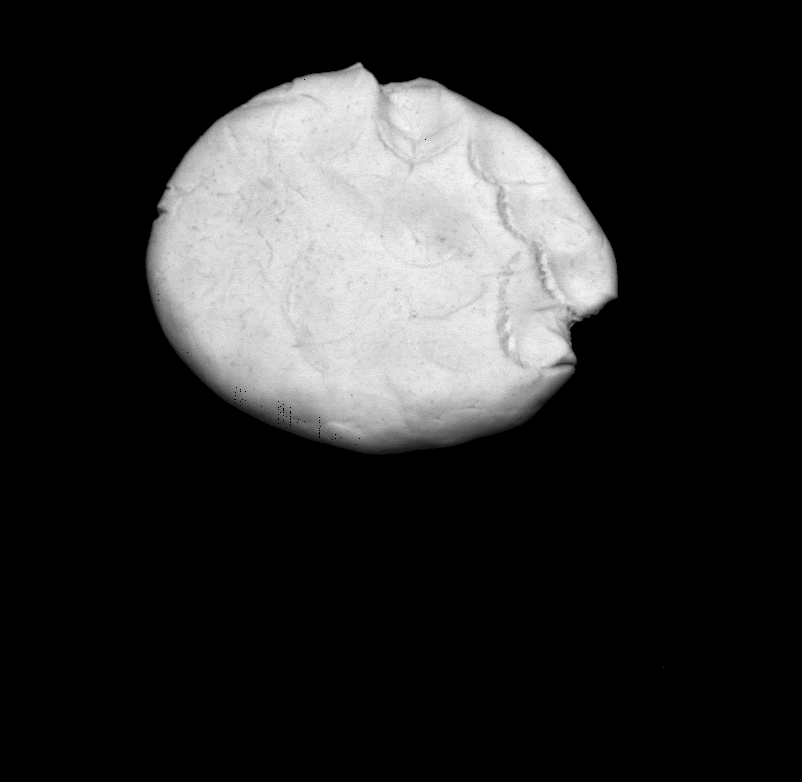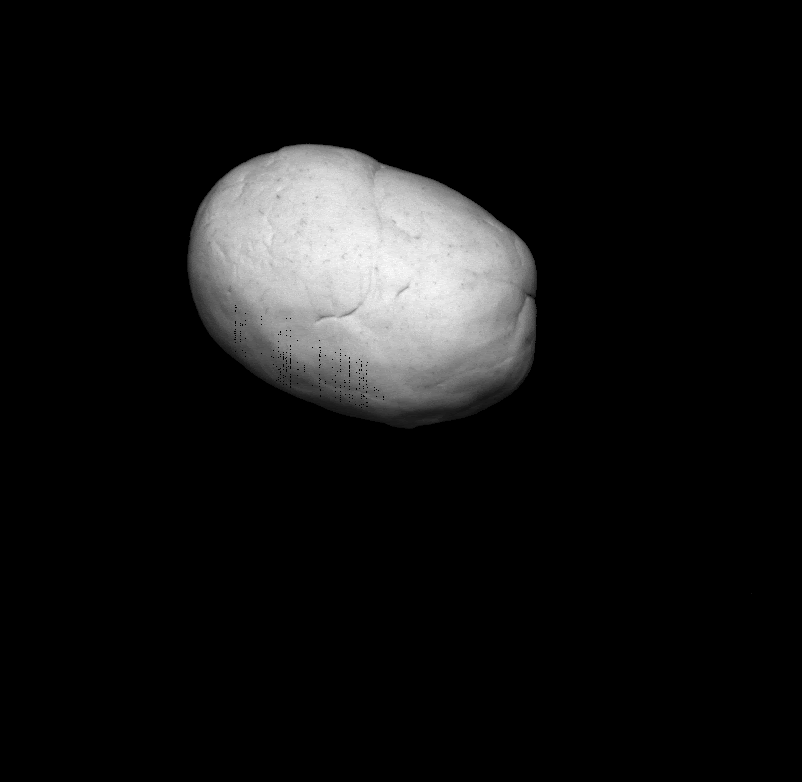


|
The source code and design of this webpage is adapted from Ref-NeRF project page. We would like to thank the authors for the inspiration. |

